
Scaling WebSockets to Billions of Connections Globally: Lessons from Socket.io, Pusher, and PubNub
How Ably delivers 1.5 billion daily WebSocket connections across 11 datacenters—and why this combination was considered impossible.

Last Wednesday, I wrote about how Ably maintained zero impact during the AWS US-EAST-1 outage.
Today: another thing our competitors probably thought was impossible.
Scaling WebSockets globally to billions of connections daily.

Standing on the Shoulders of Giants
When we started building Ably in 2016, we didn’t start from scratch. We studied the platforms that came before us, learned from their innovations, and understood their trade-offs.
Three pioneers shaped our thinking:
1. Socket.io: The WebSocket Pioneer
Guillermo Rauch (now CEO of Vercel) created Socket.io and showed the world that WebSockets could be accessible to mainstream developers. Before Socket.io, WebSockets were complex, low-level, and hard to use. After Socket.io, millions of developers could add realtime features with elegant, event-driven APIs.
Socket.io pioneered:
Native WebSocket protocol with automatic fallbacks
Event-based messaging that just made sense
Open source accessibility (free forever)
Excellent developer experience
What we learned: WebSocket can have beautiful APIs. Developers don’t want to think about protocols—they want to think about features.
2. Pusher: The Managed Platform
Pusher took Socket.io’s WebSocket approach and made it a managed service. No servers to run. No Redis to configure. No DevOps burden. Just beautiful APIs and infrastructure that worked.
Pusher proved:
Developers would pay for zero-operations platforms
Developer experience matters as much as features
WebSocket-based managed services were viable businesses
What we learned: The future isn’t self-hosting libraries—it’s managed platforms that eliminate operational complexity.
3. PubNub: The Global Scale Ambition
PubNub demonstrated that globally distributed pub/sub infrastructure could work at scale. With 15+ points of presence worldwide, they showed ambition for true internet-scale realtime messaging.
What we learned: Developers building global applications need infrastructure that’s already distributed globally. Single-region solutions create latency problems.
The Trade-Offs Each Made
Each platform achieved something remarkable. But each also made architectural trade-offs that created limitations:
Socket.io: Elegance Without Scale Operations
Socket.io is a library, not a managed platform. You host it yourself.
The trade-off:
✅ Strength: Free, open source, complete control
❌ Limitation: Full DevOps burden, manual clustering, single-region (self-hosted)
Connection limits: Production deployments typically hit 10,000-30,000 concurrent connections per Node.js instance before performance degrades. Beyond this, you need to manually cluster using Redis and sticky sessions.
Guillermo Rauch’s own acknowledgment (from Software Engineering Daily podcast):
“I suffered from that quite a bit with Socket.io, which was one of my open source projects because there was only so much I could do to like kind of transfer the best practices of how to scale it at a massive concurrency. I could write a readme, but that’s, that’s as far as open source can typically go.”
Real-world evidence:
Trello initially used Socket.io but encountered “problems with scaling up to more than 10K simultaneous client connections” and eventually built a custom WebSocket implementation handling “nearly 400,000” connections
Disney+ Hotstar evaluated Socket.io but selected MQTT instead for their social feed infrastructure
The constraint: Socket.io wasn’t designed for internet scale. It excels at small-to-medium deployments where you want flexibility and control. At massive scale, the operational complexity becomes overwhelming.
Pusher: WebSockets, But Single-Region
Pusher took the right approach with WebSockets and managed infrastructure. But each Pusher app lives in a single cluster—one datacenter location.
Available clusters: 9 regional options (N. Virginia, Ohio, Oregon, Ireland, Singapore, Mumbai, Tokyo, Sydney, São Paulo)
The trade-off:
✅ Strength: Simple architecture, WebSocket protocol, zero operations
❌ Limitation: Single-region per app means higher latency for global users, no automatic geographic failover
From Pusher’s documentation on why they chose single-region:
“Consistency is important to Pusher, and they are not happy with the compromises needed to replicate data across clusters, such as inaccurate ordering of messages, dropped messages, or increased latency.”
This is a valid architectural choice—single-region simplifies operations and guarantees consistency. But it creates trade-offs:
Users far from your selected cluster experience higher latency
If your datacenter goes down, your entire app is affected
No automatic failover between clusters—you must implement manual failover logic
The constraint: Pusher optimized for simplicity over geographic distribution. Great for regional applications. Problematic for global ones.
PubNub: Global Distribution, But Not WebSockets
PubNub demonstrated global distribution with 15+ points of presence (exact locations not publicly specified). But here’s where it gets interesting.
PubNub’s own documentation reveals the protocol reality:
Their blog claims (WebSockets vs REST article):
“At PubNub we have taken WebSockets to extreme scale and reliability, being able to service millions of devices across the globe and billions of messages each day being sent across the wire.”
Their technical guide says (WebSockets guide):
“WebSocket shortcomings can be difficult to manage if you are not an expert in building real-time systems.”
“PubNub takes a protocol-agnostic stance, but in our current operations, we have found that long polling is the best bet for most use cases.”
Their support documentation confirms (Subscribe Long Poll Mechanism):
Uses HTTP long-polling, not WebSockets
Default timeout: 310 seconds
Presence events use “~280s server pings”
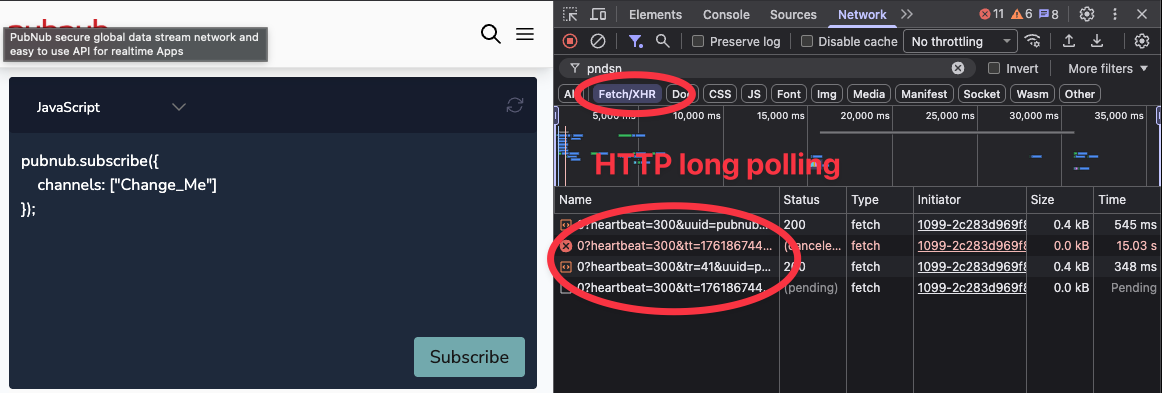
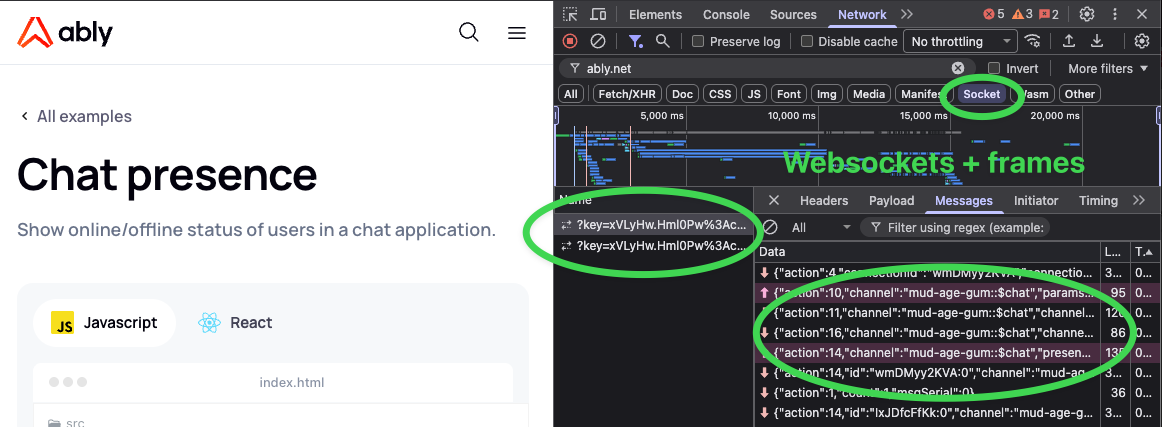
The trade-off:
✅ Strength: Global distribution, multi-region architecture
❌ Limitation: HTTP long-polling instead of WebSockets (higher latency, more overhead, stateless connections)
Why HTTP long-polling matters:
Higher latency (repeated connection setup/teardown vs persistent WebSocket)
Higher overhead (HTTP headers on every request)
Stateless (harder to provide ordering guarantees—more on this Monday)
More bandwidth usage
Worse mobile battery life
You can verify this yourself: Open browser DevTools → Network tab. Connect to a PubNub demo. You’ll see HTTP GET requests, not WebSocket frames.
The constraint: PubNub achieved global distribution but traded away WebSocket’s technical benefits.
Platform Comparison Visualised
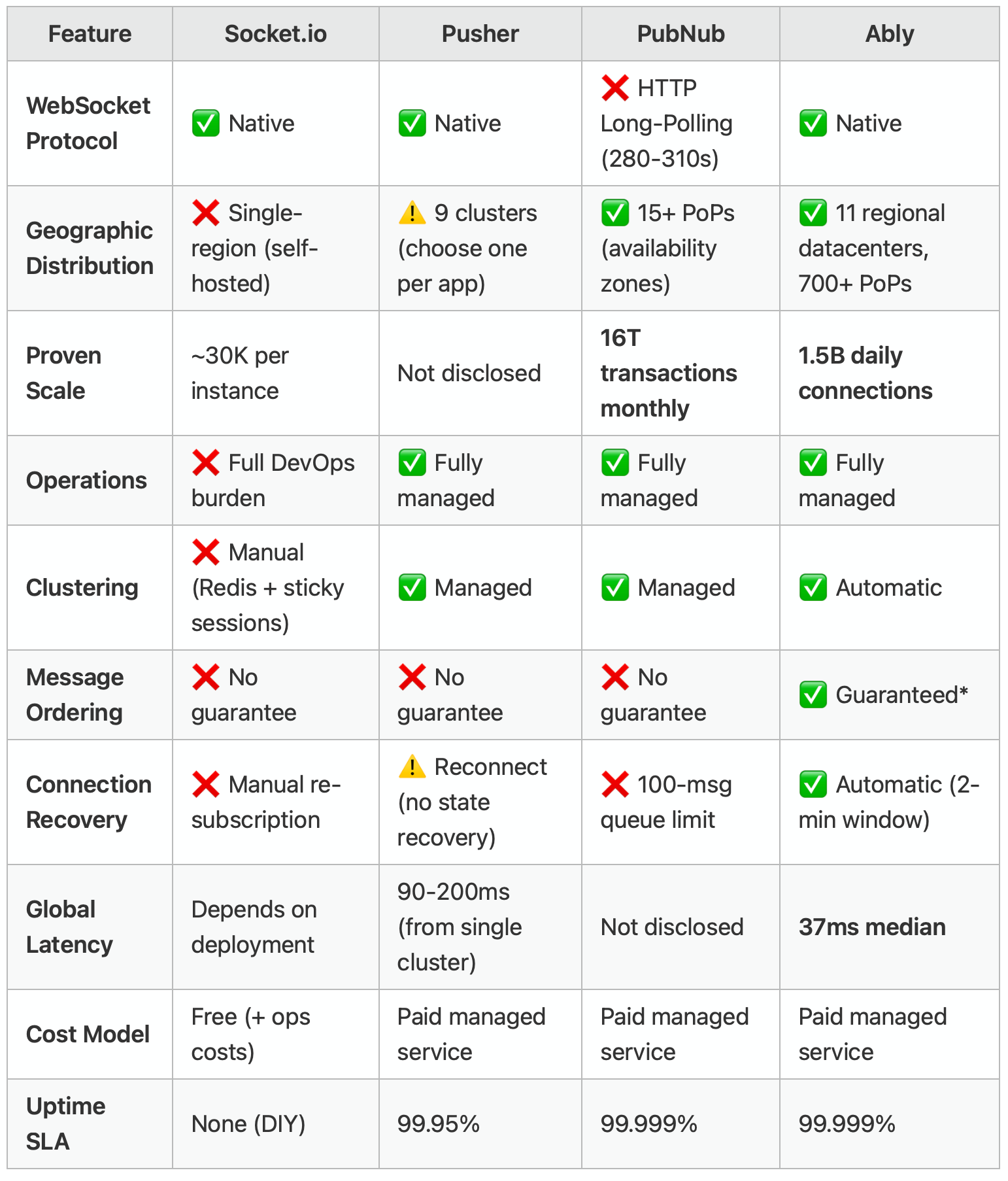
Why This Combination Is Hard
None of these platforms could deliver all four simultaneously:
✅ Native WebSocket protocol (not HTTP long-polling)
✅ Globally distributed architecture (not single-region)
✅ Billions of connections at scale
✅ Reliability guarantees (ordering, delivery, recovery)
Why? Because combining these is genuinely difficult engineering:
Challenge 1: WebSocket State Management Across Regions
WebSockets are stateful, persistent connections
Distributing state across global datacenters while maintaining consistency is complex
Most platforms chose either WebSockets OR global distribution, not both
Challenge 2: Ordering Guarantees in Distributed Systems
The CAP theorem means trade-offs between consistency, availability, and partition tolerance
Most platforms prioritize availability over strong ordering
Providing ordering guarantees at global scale requires careful architectural decisions (more on this Monday)
Challenge 3: Operations at Scale
Socket.io: Operations burden falls on users (manual clustering, Redis, monitoring)
Pusher: Operations managed, but single-region limits scale
PubNub: Global operations, but HTTP’s stateless nature limits capabilities
What Ably Built
At Ably, we asked: Could we achieve all four?
Could we combine:
Socket.io’s WebSocket elegance
Pusher’s zero-operations experience
PubNub’s global distribution ambitions
Plus reliability guarantees none of them provide
Turns out: yes. But it required building distributed infrastructure from the ground up with all four as first-class requirements.
The Architecture
Multi-region active-active: 11 globally distributed core routing datacenters
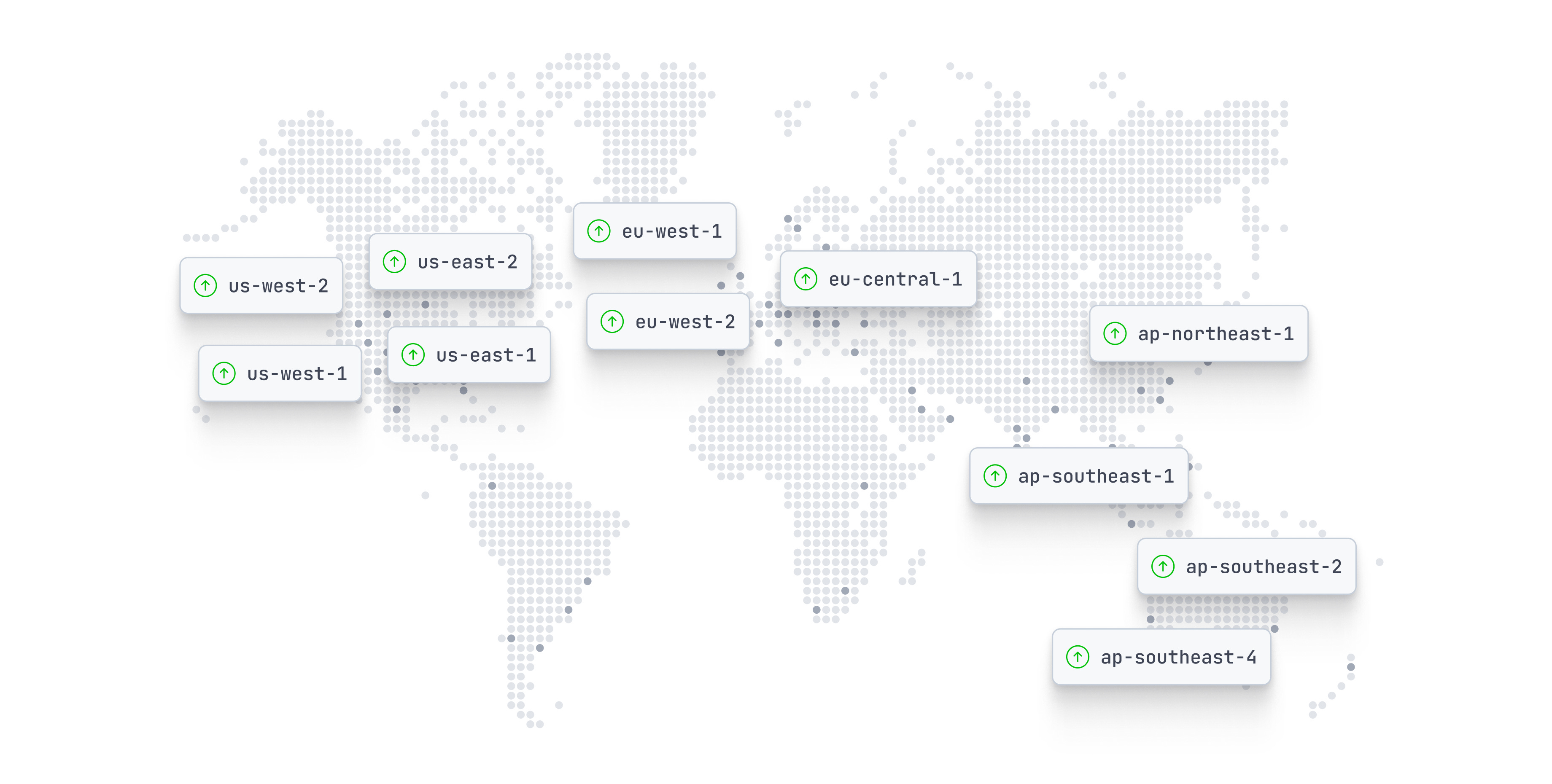
Each region operates independently
Regions communicate peer-to-peer (no central hub)
Failure in one region doesn’t cascade to others
700+ edge acceleration points globally
Native WebSocket protocol with intelligent fallbacks:
WebSocket specification implemented in all SDKs
Automatic fallback to Comet/long-polling only when WebSocket unavailable
Binary protocol support (MessagePack) for efficiency
Open source SDKs so developers can verify implementation
Automatic clustering and failover:
Unlike Socket.io’s manual Redis clustering, Ably’s clustering is built-in
Unlike Pusher’s single-region design, Ably automatically routes to nearest healthy datacenter
Connection state preserved during failover
2-minute connection recovery window with automatic message recovery
Reliability guarantees:
Message ordering for messages from a publisher over a single connection
Exactly-once delivery with idempotency
Automatic connection state recovery
(More on ordering guarantees in Monday’s post)
The Scale We’re Running
Ably by the numbers (current platform stats):
2 trillion realtime API transactions monthly
1.5 billion daily WebSocket connections
30 billion monthly connections
2.4 billion devices reached monthly
37ms median roundtrip latency globally
6.7ms average edge message delivery latency
11 globally distributed regions
700+ edge acceleration PoPs
99.999% uptime SLA (achieved 100% uptime for 5+ consecutive years)
For context:
Ably handles ~50,000x more connections than Socket.io’s per-instance limit (1.5B daily vs 30K per instance)
Delivers this across 11 datacenters vs single-region deployments
With sub-40ms global latency vs routing all traffic to one location
The Engineering Philosophy
Guillermo Rauch was right: You can’t transfer “massive concurrency” best practices through documentation alone.
That’s why we built a platform, not a library.
Our philosophy: Do the hard infrastructure work so our customers don’t have to.
Socket.io requires customers to:
Manage servers, Redis, load balancers
Configure sticky sessions and clustering
Implement monitoring and failover
Handle scaling, security, and operations
Ably handles all of this:
Zero servers to manage
Zero Redis to configure
Zero load balancers to tune
Automatic scaling, security, and operations
This isn’t about Socket.io being wrong—it’s about different tools solving different problems. Socket.io excels at providing free, flexible WebSocket capabilities for small-to-medium scale. Ably provides internet-scale infrastructure with enterprise guarantees.
The validation isn’t just our engineering—it’s that customers from all three platforms have migrated to Ably when they outgrew their original solution’s architectural constraints. Common themes: operational complexity at scale, geographic distribution requirements for global user bases, and the need for reliability guarantees their previous platform’s architecture couldn’t provide.
What’s Coming Monday
Today’s post focused on achieving WebSockets at global scale—combining protocol benefits with geographic distribution and operational simplicity.
But WebSockets alone don’t guarantee reliability.
Monday: How Ably’s architecture enables guarantees they can’t provide—and why this matters for financial systems, gaming, collaboration, chat and any application where message sequence matters.
See you Monday.
Matthew O’Riordan
Founder & CEO, Ably
Verify Everything
I’m making bold claims. Don’t trust me—verify the evidence:
1. Socket.io Connection Limits:
Production reports: “many people have issues getting above 30k connections”
Trello case study: Problems scaling beyond 10K
Socket.io clustering docs: Manual Redis + sticky sessions required
2. Pusher Single-Region Architecture:
Cluster configuration: “When you create a Channels app, you can choose which cluster it exists in”
No automatic failover: “Channels has no built in failover between clusters”
3. PubNub HTTP Long-Polling:
WebSocket guide: “long polling is the best bet for most use cases”
Subscribe documentation: 310-second timeout
Presence events: “~280s server pings”
Verify yourself: Open DevTools, test their demo
4. Ably Architecture:
Platform architecture: Multi-region design
WebSocket specification: Protocol implementation
Open source SDKs: Verify implementation yourself
Network map: 11 regions + 700+ edge points
The evidence is public. The data is verifiable. The architectural differences are documented.