
Stream integrity in globally distributed systems: Why most platforms can't guarantee it
How Ably provides message ordering and exactly-once delivery at global scale—and why this combination was considered impossible

When a competitor called our AWS outage results “impossible,” it made me realise I need to talk more about the things we’ve achieved here at Ably, that are supposedly impossible.
First, we talked about maintaining zero impact during a significant AWS outage. All while PubNub experienced 10+ hours of degraded service.
Then, we covered scaling WebSockets to billions of connections globally. Highlighting the achievements of Socket.io, Pusher, and PubNub.
In this post: Another impossible thing by Ably. Guaranteeing stream integrity in a globally distributed system.

What is stream integrity?
When developers build realtime applications, they need confidence that:
Messages arrive in order (sequencing matters)
Messages arrive exactly once (no duplicates)
Messages don’t get lost (even during network interruptions)
These aren’t “nice to have” features. They’re fundamental for building reliable realtime applications.
Examples where ordering matters:
Chat: Message threading, reactions to specific messages
Streaming AI: OpenAI, Anthropic, Gemini APIs send token deltas—out-of-order = garbled responses
Collaborative apps: Delta updates without CRDTs require strict ordering to prevent divergence
Financial systems: Price updates, transaction sequences
Gaming: Command sequences determine state
The developer shouldn’t have to think about this. Just like TCP/IP guarantees packet ordering, a realtime platform should guarantee message ordering so you focus on building features, not reliability infrastructure.
Standing on the shoulders of the early pioneers
When we started building Ably, we learned from the realtime platforms that came before us:
Socket.io (by Guillermo Rauch, now CEO of Vercel): Pioneered elegant WebSocket APIs that made realtime accessible to mainstream developers.
Pusher: Proved that managed platforms could eliminate DevOps burden, scale WebSocket infrastructure and do this delightfully for developers.
PubNub: Demonstrated ambition for global-scale realtime messaging across many points of presence.
Each achieved something remarkable. But each also made architectural trade-offs that limit their ability to provide stream integrity guarantees.
Why they can’t guarantee ordering
Socket.io: clustering introduces race conditions
Socket.io is a brilliant open-source library designed for self-hosting. Not as a managed platform.
The constraint: Beyond ~10K-30K connections per instance, you need to cluster multiple servers using Redis. When messages flow through Redis Pub/Sub across instances, race conditions emerge
Result: Socket.io has no ordering guarantees.
From creator Guillermo Rauch (Software Engineering Daily):
“I suffered from that quite a bit with Socket.io... there was only so much I could do to transfer the best practices of how to scale it at a massive concurrency. I could write a readme, but that’s as far as open source can typically go.”
Provides: Elegant WebSocket API, flexibility, open source.
Doesn’t provide: Ordering guarantees at scale, managed clustering, geographic distribution.
Pusher: parallel processing sacrifices ordering
Pusher uses native WebSocket protocol (unlike PubNub) and provides managed infrastructure - both positive.
The constraint: Each app lives in a single cluster. Within that cluster, messages are processed in parallel for throughput.
From Pusher’s documentation (“Why Don’t Channels Events Arrive In Order?”):
“Messages are processed by many machines in parallel on our backend.”
Result: Pusher has no ordering guarantee.
Their recommended workaround: Add sequence numbers, buffer messages, sort client-side, handle gaps. You’ve built a reliability layer on top of the platform.
Provides: Native WebSockets, managed infrastructure, zero operations.
Doesn’t provide: Ordering guarantees, multi-region per app, connection state recovery.
PubNub: Stateless HTTP can’t guarantee sequence
As covered in my previous post, Scaling Websockets to Billions of Connections Globally, PubNub uses HTTP long-polling (280-310s timeouts) instead of WebSockets.
From PubNub’s support docs (“Does PubNub guarantee the order of messages?”):
“No. If your application requires strict ordering, we recommend you add a sequence field to the message payload and order by it.”
The reason: HTTP long-polling is stateless. Each message is an independent HTTP request. Concurrent requests can complete in different orders.
On delivery: “PubNub is not a guaranteed message delivery service.”
On recovery: “The default message queue size is 100 messages. Publishing over 100 messages in the window of the subscribe reconnect time inevitably results in older messages overflowing the queue and getting discarded.”
Translation: Disconnect during high volume = permanent message loss.
Result: PubNub has no ordering guarantee
Provides: Global distribution (15+ points of presence), managed infrastructure.
Doesn’t provide: Ordering guarantees, WebSocket protocol, reliable delivery beyond 100-message queue.
The Pattern: Architectural trade-offs
Each platform made conscious design choices:
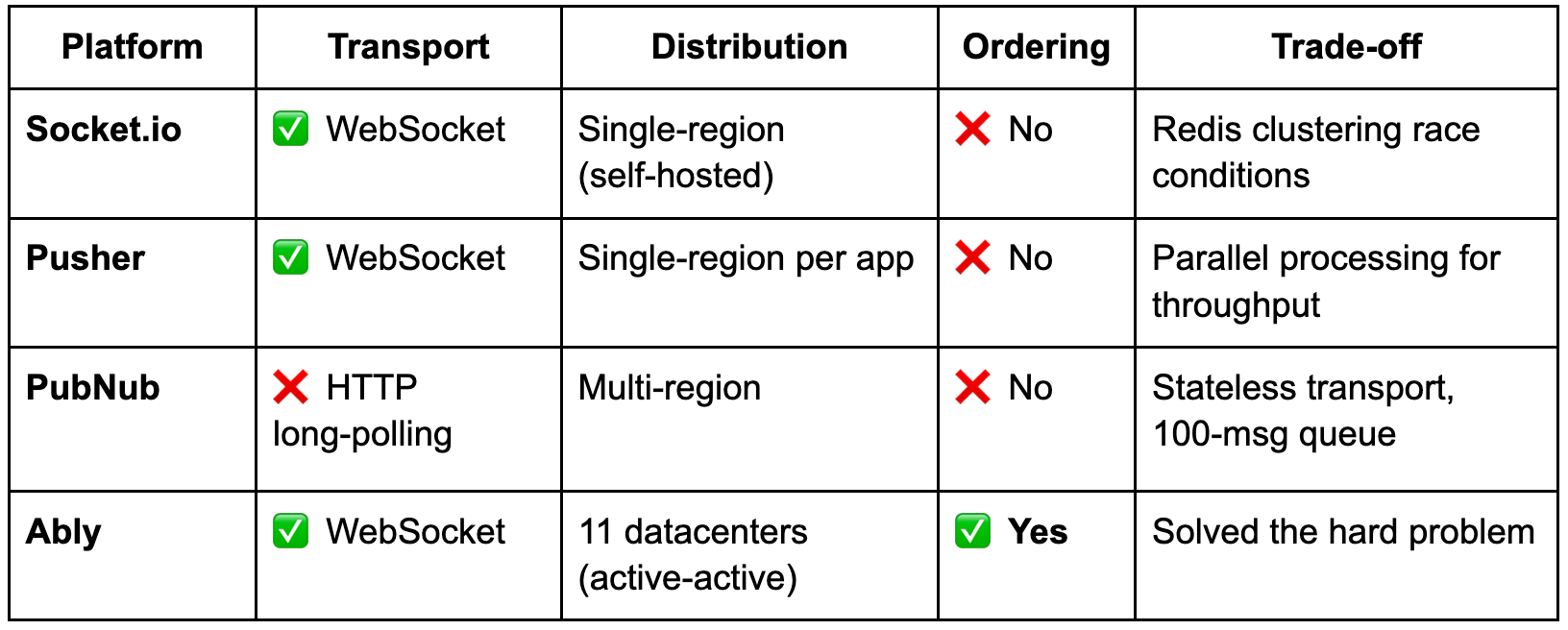
These aren’t failures. They’re architectural decisions that made sense for different goals. But they create a gap: What if you need global distribution AND stream integrity guarantees?
How Ably achieves both
When we built Ably, we asked: Could we provide stream integrity guarantees in a globally distributed system? Not single-region. Not single-server. But across many globally distributed datacenters with sub-40ms global latency?
The answer: Yes. But it required building distributed infrastructure from the ground up with stream integrity as a first-class requirement.
Our Guarantees
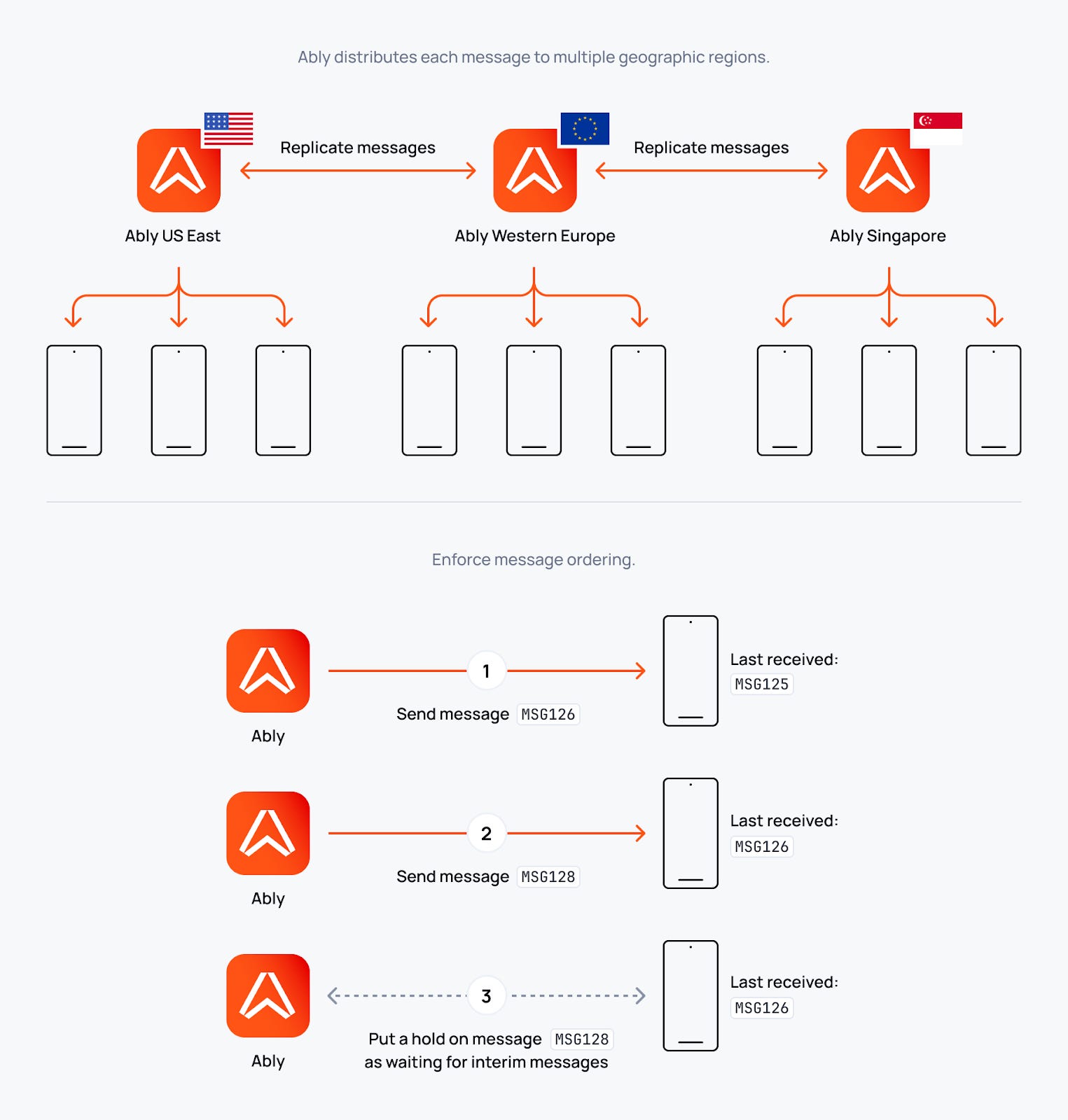
1. Message Ordering
Messages from any publisher over a single connection are delivered to all subscribers in the same order.
How it works: Each message gets a unique serial number at the time of publication. These serial numbers ensure subscribers see messages from that publisher in the correct sequence. Even across regions.
We achieve this through WebSocket’s persistent connection property plus sequential message processing. And we do it while maintaining 6.5ms message delivery latency within a region- proving that ordering guarantees don’t require sacrificing performance.
Read more: Data Integrity in Ably Pub/Sub
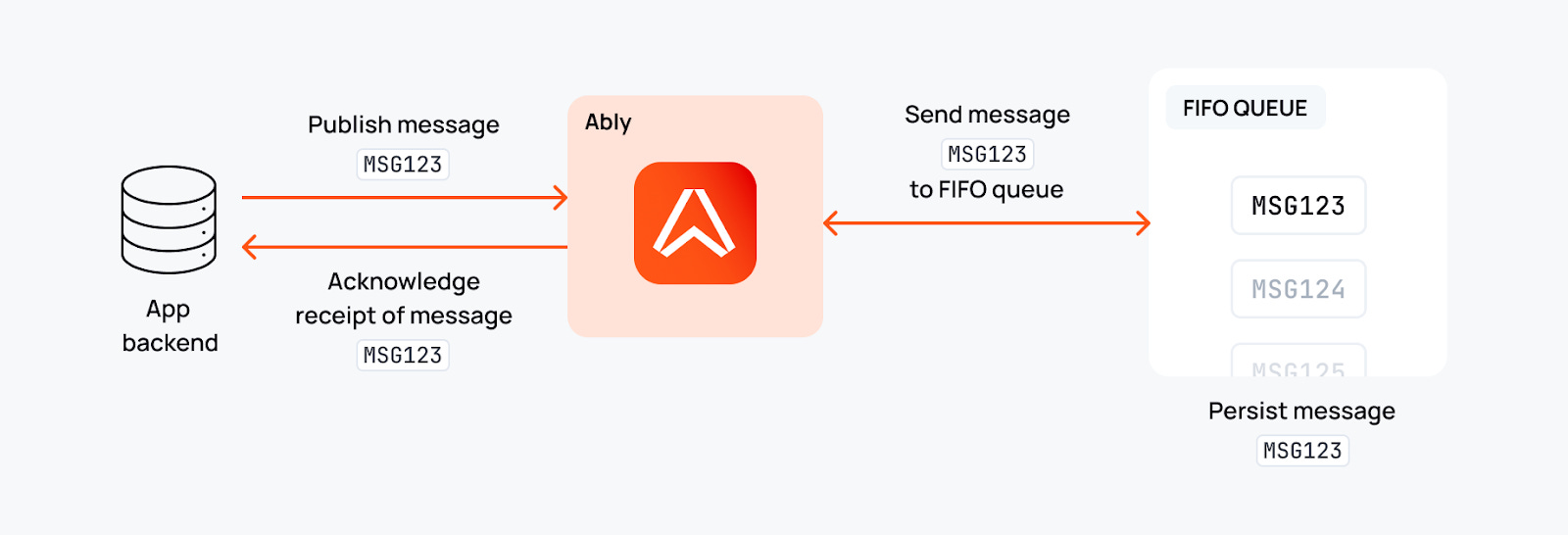
2. Exactly-once delivery
Once we acknowledge receipt of a message, we guarantee it will be delivered exactly once. No duplicates.
How it works: Idempotent publishing with unique message IDs, plus clients resume with a serial number. That serial number tells us exactly where the client left off in the stream, so even if you lose connection, you resume from precisely where you left off - guaranteeing you never get duplicates.
We chose this model (client tracking position via serial number) instead of server tracking client position because otherwise you can’t provide guaranteed ordering in a distributed system.
Read more: Achieving Exactly-Once Delivery
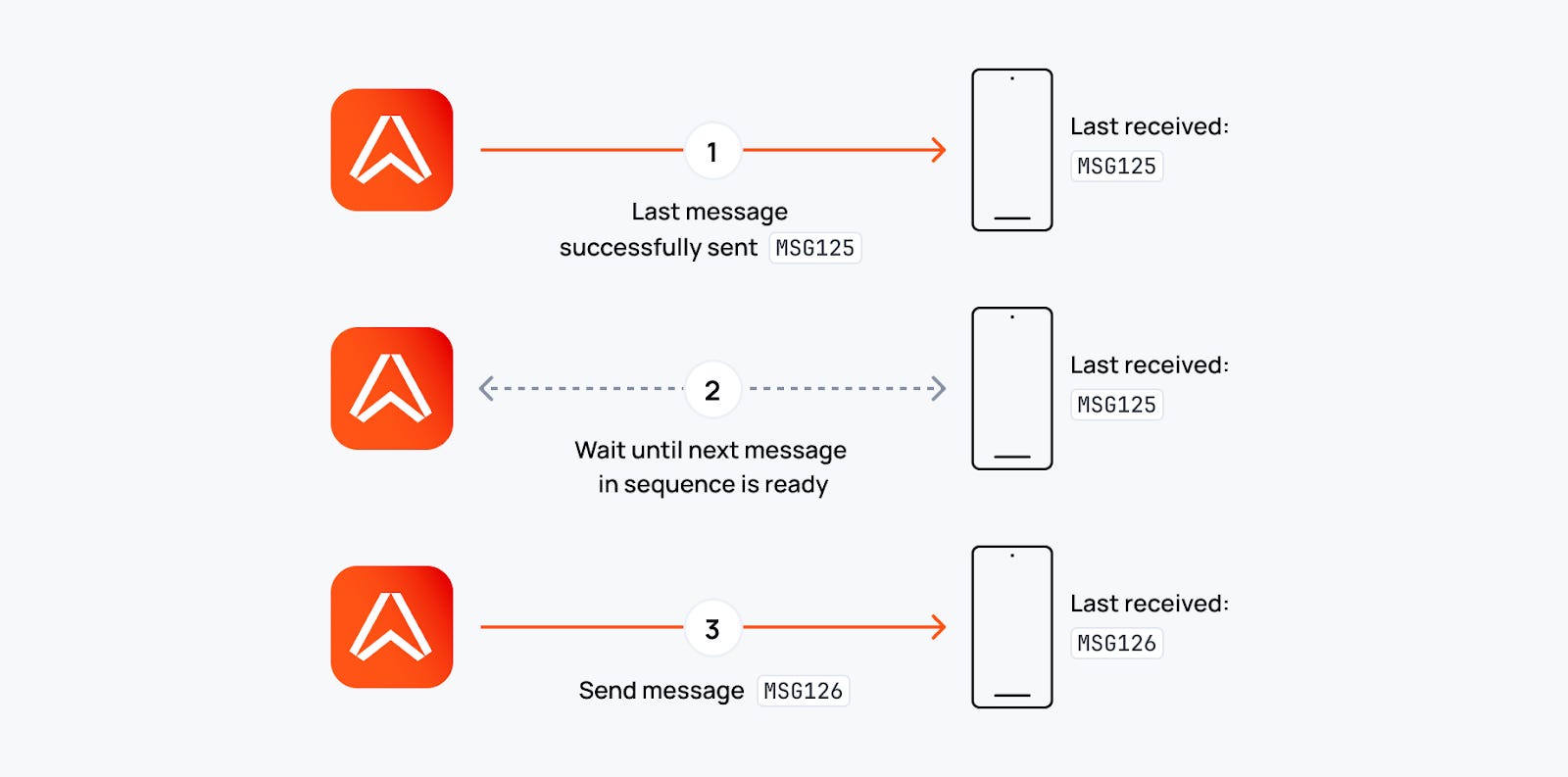
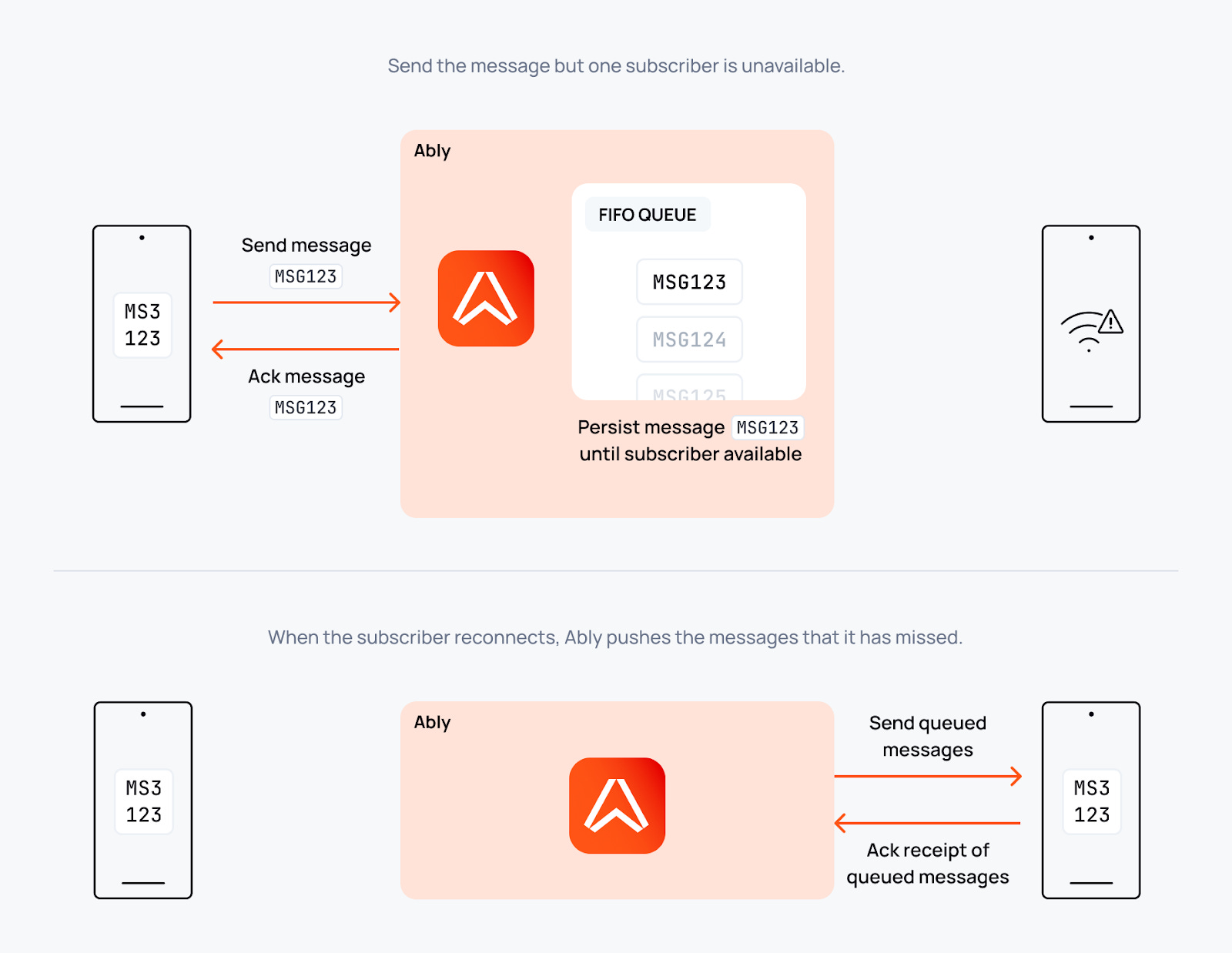
3. Connection state recovery
If a client disconnects briefly (within 2 minutes), we automatically resume with preserved state and zero message loss.
For longer disconnections, our History API extends beyond that window, allowing clients to catch up on any duration of missed messages.
No manual re-subscription. No message gap detection. No custom recovery logic.
These guarantees are in our SLA. They’re quantified in our Four Pillars of Dependability. They’re not marketing. They’re engineering commitments.
The global ordering nuance
An important technical point: While it’s technically possible to enforce a single global ordering of all messages across all publishers, doing so would fundamentally compromise the low-latency, fault-tolerant distributed system that realtime applications require.
Example: Publisher A in the US and Publisher B in Asia both send messages simultaneously. If we enforced global ordering, messages from nearby regions would be held back awaiting messages from distant regions, adding significant latency to all messages globally. Instead, a subscriber in Europe receives each message with minimal latency, with the tradeoff being that network physics determines which arrives first, not some artificial global sequence.
What we DO guarantee: Every subscriber sees messages from each publisher (using a transport that supports ordering, such as WebSockets) in the same order. This is “causal consistency per client” and it’s what actually matters for real-world applications.
Why this solves real problems: Developers need confidence that each participant’s messages maintain order. Chat from one user stays sequential. Token deltas from one AI stream arrive in sequence. Price updates from one exchange remain ordered.
The alternative (single global coordination point) would:
Add latency to every message globally
Create a single point of coordination and congestion
Sacrifice geographic distribution benefits
Introduce a critical failure point
Not solve any real-world use case we’ve encountered
Our approach: Guarantee ordering from each publisher while optimizing for low latency through regional independence.
Read more: Chat Architecture for Reliable Message Ordering
Making the impossible possible at global scale
Providing these guarantees in a single datacenter is achievable, but hard. Providing them across 11 globally distributed datacenters with active-active replication? That takes engineering at its finest — and exactly the kind of challenge we thrive on.
As mentioned in my post about the AWS outage, we operate many datacenters globally including two in US-East alone.
The engineering required to make this work includes:
Persistent WebSocket connections
Regional message sequencing with serial numbers
Cross-region replication with ordering preservation
Connection state management across failover
Idempotency tracking across distributed nodes
2-minute recovery windows with queued messages
This is not impossible. It’s just crazy difficult and expensive engineering work that we chose to do.
Developers shouldn’t have to implement reliability infrastructure. They should assume these basics - even though they’re extremely difficult - are in place.
Just like TCP/IP lets you operate at a higher level, realtime infrastructure should let you focus on features, not sequence numbers and deduplication.
What’s coming Wednesday
Today we talked about stream integrity guarantees that most platforms can’t provide.
Wednesday’s topic: Pricing that rewards success, not penalizes it (impossible? No)
MAU models and bundled pricing ultimately result in billing surprises or inefficient spending. We’ll talk through why transaction-based transparency matters and how we approach pricing that aligns with customer success.
See you Wednesday.
Matthew O’Riordan
Founder & CEO, Ably
Verify Everything
I’m making bold claims. Don’t trust me verify the evidence:
1. First Gen Realtime Solutions Documentation:
Socket.io: Clustering documentation showing manual Redis + sticky sessions required
2. Ably Documentation:
Four Pillars of Dependability - Performance, Integrity, Reliability, Availability
Data Integrity in Ably Pub/Sub - Technical implementation details
The evidence is public. The data is verifiable. The architectural differences are documented.